Das Problem der Stichprobe
In den meisten Situationen ist es unmöglich die gesamte Population zu vermessen, so dass man sich mit einer Stichprobe zufrieden geben muss. Die Population wird häufig auch als Grundgesamtheit bezeichnet und Ziel des Experimentes sollte es sein, eine möglichst repräsentative Stichprobe zu verwenden.
Dieses Problem mündet natürlich in einem intelligenten Versuchsdesign. Aber selbst bei der vermutlich repräsentativsten Stichprobe muss davon ausgegangen werden, dass die statistischen Größen dieser Stichprobe nicht denen der Population entsprechen müssen.
Mittelwert der Stichprobe
Aus diesem Grund ist der Mittelwert der Stichprobe nur eine Schätzung des Populationsmittelwertes. Um dies deutlich zu machen, wird satt \( \mu \) die Symbolik \( \bar{X} \) für den Mittelwert der Stichprobe verwendet! \[ \bar{X} = \frac{1}{n} \sum_{i=1}^n X_i \]
Varianz einer Stichprobe
Das gleiche gilt auch für die Varianz der Stichprobe. Zur Erinnerung, die Varianz der Grundgesamtheit ist gegeben durch:
[ \sigma^2 = \frac{1}{N} \sum_{i=1}^N (X_i - \mu)^2 ]
Für die Varianz der Stichprobe steht uns leider weder alle \( N \) Werte zur Verfügung, noch ist im Normalfall das Populationsmittel \( \mu \) bekannt. Es bleibt einem also nichts anderes übrig, als sich mit den \( n \) Werten und dem Mittelwert \( \bar{X} \) der Stichprobe als Schätzer für die Population zufrieden zu geben. Jedoch besitzt unser Schätzer für die Varianz dann einen systematischen Fehler, da man die Varianz immer unterschätzt. Dies liegt daran, dass man für das Berechnen des Mittelwertes der Stichprobe einen sogenannten Freiheitsgrad verliert. Folgendes Beispiel soll dies verdeutlichen: Es sei der Mittelwert einer Stichprobe mit 5 Messwerten \( \bar{X}=2 \) gegeben. Wieviele der 5 Messwerte lassen sich dadurch frei wählen? Die Antwort lautet: Nur vier, denn der letzte Messwert muss so gewählt werden, dass der Mittelwert der Stichprobe stimmt. Unser Beispiel hat also einen Freiheitsgrad durch den Mittelwert verloren. Man kann sich den systematischen Fehler aber auch geometrisch verdeutlichen. Die Formel der Varianz ist eine normierte Abweichung vom Mittelwert. Wenn wir aber den Mittelwert aus den Daten schätzen, dann folgt der Mittelwert den Daten, wodurch die Abweichung vom Mittelwert unterschätzt wird. Um dem verlohrenen Freiheitsgrad gerecht zu werden, lautet die Formel für die Varianz der Stichprobe \( s^2\): \[ s^2 = \frac{1}{\mathbf{n-1}} \sum_{i=1}^n (X_i -\bar{X})^2 \]
Standardfehler des Mittelwertes
Wenn man aus einer normalverteilten Population mit dem Mittelwert \( \mu \) und der Varian \( \sigma^2 \) eine Vielzahl von Stichproben mit einem Mittelwert \( \bar{X} \) nimmt, dann sind die Mittelwerte \( \bar{X}_i \) ebenfalls normalverteilt und diese Verteilung besitzt ebenfalls einen Mittelwert, welcher als Schätzer für den Mittelwert \( \mu \) der Population verwendet werden kann. Wie die Intuition einem schon verrät, wird die Schätzung besser, je größer die Stichproben sind. Dies repräsentiert der sogenannte Standardfehler des Mittelwertes (SEM): \[ SEM = \sigma_{\bar{X}} = \frac{\sigma}{\sqrt{n}} \]
Der \( SEM \) gibt an, wie groß der Fehler ist, den wir mit unsere Schätzung machen. Der \( SEM \) hat vor allem deshalb eine so hohe Bedeutung, weil er zur Voraussage herangezogen werden kann, in welchem Intervall sich eine bestimmte Prozentzahl unsere Stichprobenmittelwerte \( \bar{X} \) befinden werden. So fallen 95% der Stichprobenmittelwerte in das Intervall: \( \mu \pm 1.96*SEM \) Dieses Wissen ist zum Beispiel bei der bereits erwähnten intelligenten Versuchsplanung nützlich: Bei der Leukozytenzahl kann man durch die immens große Stichprobe mit guten Gewissen davon ausgehen, die statistischen Größen der Population zu kennen. So nehmen wir für dieses Beispiel mal an, dass die Leukozytenzahl eines gesunden Erwachsenen im Durchschnitt 7000 pro \( \mu l \) mit einer Standardabweichung von \( \sigma = 2500 \) ist. In einem Versuch wollen Sie den Populationsmittelwert mit Hilfe von Stichproben abschätzen. Als Vorgabe sollen 95% ihrer gemessenen Mittelwerte im Intervall \( \mu \pm 100 /\mu l \) liegen. Die Frage ist, wie groß müssen Ihre Stichproben sein, um dieser Anforderung gerecht zu werden?
[ \begin{aligned} 1.96*SEM &= 100 \ 1.96 * \frac{\sigma}{\sqrt{n}} &=100 \ 1.96 * \frac{2500}{\sqrt{n}} &=100 \ \frac{2500}{\sqrt{n}} &= 51 \ \sqrt{n} &= 49 \ n &= 2401 \end{aligned} ]
Ihre Stichproben sollten also mindestens 2401 Personen groß sein!
Wenn die Populationsgrößen unbekannt sind
Das man jedoch die statistischen Größen der Population kennt, ist eher die Ausnahme. Wenn man aber nur die Daten einer Stichprobe zur Verfügung hat, bleibt einem wieder nichts anderes übrig, als Mittelwert \( \bar{X} \) und Standardabweichung \( s \) der Stichprobe als Schätzung zu verwenden: \[ SEM = s_{\bar{X}}=\frac{s}{\sqrt{n}} \]
Aber was hat man dadurch gewonnen? Man kann testen, ob zum Beispiel der Mittelwert der Stichprobe in das 95% Intervall um einen hypothetischen Populationmittelwert \( \mu \) fällt, oder ob die Stichprobe signifikant verschieden ist. Mit Hilfe des Quotienten: \[ Z = \frac{\bar{X} - \mu_{\text{hypothetisch}}}{SEM} \]
kann man den Wert der sogenannten Z-Statistik ausrechnen, was einer Standardnormalverteilung mit N(0,1) entspricht. Wenn zum Beispiel \( -1.96 > Z > 1.96 \) ist, dann liegt \( Z \) außerhalb des Intervalls, wo 95% der Mittelwerte \( \bar{X} \) zu erwarten wären. Aber auch hier ist noch eine Korrektur notwendig. Da zu kleine Stichproben nur wenig repräsentativ sind, sind sie nur sehr schlechte Schätzer für das Populationsmittel und dessen Varianz. Die Verteilung der Mittelwerte kleiner Stichproben ist breiter und flacher als die einer Standardnormalverteilung. Das hat Auswirkungen auf das Konfidenzintervall, wo 95% der Werte zu erwarten sind. Dies spiegelt sich in der sogenannten t-Statistik wieder, wobei es sich um eine Korrektur für kleine Stichproben handelt und welche bei \( n\rightarrow\infty \) in die Z-Statistik übergeht. Die folgende Tabelle zeigt ein paar Beispiele:
| Stichprobengröße \( n\) | 95% Konfidenzintervall |
|---|---|
| 4 | \(\pm \) 3.182 |
| 60 | \(\pm \) 2.001 |
| 200 | \( \pm \) 1.972 |
| 1000 | \(\pm \) 1.962 |
| \( \infty \) | \( \pm \) 1.96 |
Der t-Test
Stellen Sich vor, Sie züchten Forellen in einem See und Sie wollen die Forellen ernten, sobald diese im Durchschnitt 80\,cm groß sind. Um das Wachstum der Forellen zu überprüfen, fangen Sie 9 Fische. Ihre Nullhypothese lautet dabei, dass die Fische aus einer Population mit durchschnittlich 80\,cm Größe stammen. Die alternative Hypothese ist, dass die Fische aus einer Population stammen, die nicht die erforderliche Durchschnittsgröße hat. Die 9 zufälligen Fische haben folgende Größe (in cm): \[ 70 \ \& \ 81 \ \& \ 77 \ \& \ 75 \ \& \ 75 \ \& \ 74 \ \& \ 79 \ \& \ 76 \ \& \ 83 \]
Versuchen Sie eine Bauchentscheidung zu treffen, ob die Fische im See zu klein, zu groß oder im Durchschnitt 80cm groß sind. Der folgende Code berechnet die benötigten Werte in R:
> fische <- c(70,81,77,75,75,74,79,76,83) > n <- 9 > m <- mean(fische) [1] 76.667 > s <- sd(fische) [1] 3.905 > SEM <- s/sqrt(n) [1] 1.302 > t8 <- (m - 80) / SEM [1] -2.561
Da Sie mit der Stichprobe den Mittelwert als Schätzung für das Populationmittel berechnen, verlieren Sie einen Freiheitsgrad! Für den t-Test stehen Ihnen also nur noch 8 Freiheitsgrade zur Verfügung. Wir wollen mit 95% Sicherheit, dass unsere Stichprobe aus einer Population mit Fischen der Größe 80cm kommen. In der Standardnormalverteilung bedeutet dies, dass der geschätzte Mittelwert nicht mehr als \( \pm 1.96 * SEM \) von der Nullhypothese abweichen darf. Der errechnete Wert von \( -2.561 \) ist deutlich zu klein, jedoch muss hier beachtet werden, dass die Stichprobe nur aus 9 Fischen bestand. Es ist also wahrscheinlich, dass Extremwerte überbewertet wurden! Aus diesem Grund müssen die Werte aus der t-Statistik herangezogen werden, welche für kleine Stichproben korrigiert sind. In diesem Beispiel liegen 95% der Werte im Intervall \( \pm 2.306*SEM \) Für unsere Stichprobe bedeutet dies, dass die gefangenen Fische mit weniger als 5% Wahrscheinlichkeit die richtige Größe haben, sondern mit mehr als 95% Wahrscheinlichkeit noch zu klein sind! Wollen Sie jedoch eine höhere Sicherheit, z. Bsp. wollen Sie wissen, ob die 9 Fische mit weniger als 1% Wahrscheinlichkeit aus einer Population mit 80cm großen Fischen stammen, dann liegen 99% der Mittelwerte im Intervall \( \pm 3.355*SEM\). Für die Stichprobe heißt das, dass diese mit mehr als 1% Wahrscheinlichkeit doch aus einer Population mit einem Durchschnitt von 80cm stammen kann.
Fehler
Wie in dem Beispiel mit den Forellen deutlich wird, kann die Statistik einem nur helfen, Nullhypothesen zu widerlegen. Kein Test kann jedoch die Nullhypothese beweisen! Alles was man machen kann, ist die Nullhypothese beizubehalten und einen neuen Test zu machen, mit dem Ziel, die Nullhypothese zu widerlegen. Aber auch die Entscheidung, ob man die Nullhypothese ablehnt, hängt von der geforderten Sicherheit ab. Wenn im Forellenbeispiel uns eine 95% Sicherheit ausreicht, dann können wir die Nullhypothese ablehnen. Fordern wir aber eine 99% Sicherheit, dann müssen wir die Nullhypothese beibehalten! Aber warum verlangen wir nicht immer maximale Sicherheit? Wie das Beispiel mit den Fischen zeigt, können wir bei 99% Sicherheit die Nullhypothese nicht ablehnen, wir gehen damit aber ein höheres Risiko ein, dass die Fische doch zu klein sind. Der Fehler, dass wir die Nullhypothese ablehnen, obwohl sie richtig ist, nennt man Typ-1 Fehler. Den Fehler, dass man die Nullhypothese beibehält, obwohl sie falsch ist, nennt man Typ-2 Fehler. Das Beispiel mit den Fischen zeigt sofort, dass beide Fehler zusammenhängen. Immer wenn man den Typ-1 Fehler reduziert, vergrößert man den Typ-2 Fehler. Es ist Situationsabhängig, was die richtigen Grenzen für die Entscheidung sind. Wenn z.Bsp. die Gewinneinbuße bei zu kleinen oder zu großen Fischen sehr hoch ist, dann ist ein hoher Typ-1 Fehler besser (erstes Beispiel mit 5% Typ-1 Fehler). Wenn aber z.Bsp. das Risiko einer Infektion der Fische mit einer schweren Krankheit mit der Zeit stark zunimmt, dann ist es besser, einen höheren Typ-2 Fehler zu machen (zweites Beispiel mit 1% Typ-1 Fehler).
statistische Tests
Ein statistischer Test erscheint den meisten am Anfang etwas unverständlich, dabei ist jedoch das Prinzip hinter allen Tests das Selbe. Ausgangspunkt ist wieder das Dilemma, dass wir gerne etwas über die Population erfahren möchten, aber nur eine begrenzte Stichprobe nehmen können. Der statistische Test soll uns dann bei der Entscheidung helfen, ob unsere Stichprobe aus der vermuteten Population stammen kann. Man darf dabei niemals aus den Augen verlieren, dass auch die Population einer natürlichen Schwankung/Vielfalt unterliegt. Wenn man also zum Beispiel nur den Mittelwert der Population mit dem Mittelwert der Stichprobe vergleicht, dann ist es ja durchaus möglich, dass man nur durch Zufall Werte mit einem anderen Mittelwert in der Stichprobe hat, die aber tatsächlich aus der Population stammen. Die Frage ist also: Wie groß muss die Abweichung meiner Stichprobe sein, damit ich mir sicher sein kann, dass es kein Zufall mehr ist? Das klingt zu Beginn vielleicht etwas kryptisch, aber man stelle sich folgendes Beispiel vor:
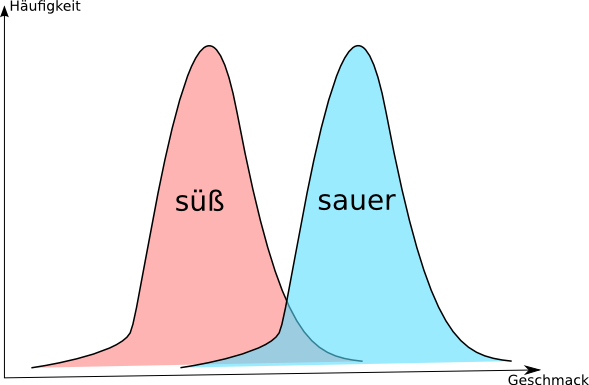
Sie sind auf einem Feld mit vielen Süßkirschen. Wie viele Kirschen müssen Sie von einem Baum probieren, damit Sie sich sicher sind, es ist eine Sauerkirsche? Für eine statistische Entscheidung müssen Sie beachten, dass nicht alle Süßkirschen gleich süß und auch alle Sauerkirschen nicht gleich sauer sind. Es ist aber auch intuitiv klar, dass die meisten Süßkirschen süß sind und saure Süßkirschen nur selten sind. Das ganze gilt vice versa auch für die Sauerkirschen. Dem ganzen liegen also 2 Verteilungen zu Grunde.
Hypothesen
Bei jedem Test müssen zwei Hypothesen aufgestellt werden:
- \(H_0\): Die Nullhypothese steht für keinen Effekt oder keine Korrelation.
- \(H_1\): Die Alternativhypothese steht für einen Effekt oder eine Korrelation.
Im Beispiel mit den Süßkirschen wäre die Nullhypothese, dass es sich nur um Süßkirschen handelt und die Alternativhypothese wäre, dass es eine Sauerkirsche ist. Doch wo legt man die Grenze fest, wann der Geschmack der Kirsche signifikant ist?
Kriterium nach Fischer
Fischer hat zur Signifikanz folgende Definition aufgestellt:
Wenn das Ergebnis des Experimentes oder noch extremere Ergebnisse weniger als 5% ausmachen, ist das Ergebnis signifikant.
Wenn in der folgenden Abbildung also die Verteilung der Süßkirschen abgebildet ist und der Pfeil den Geschmack der Stichprobe darstellt, dann ist der Bereich, der nach der Definition von Fischer für die Signifikanz ausschlaggebend ist, rot markiert.
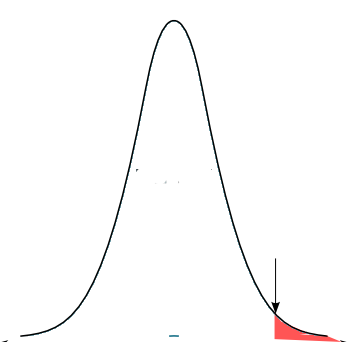
Ein statistischer Test macht also nichts anderes, als die Wahrscheinlichkeit für die beobachtete oder noch extremere Abweichung zu berechnen, unter der Annahme, dass die Nullhypothese wahr ist. Die von Fischer definierte 5% Schwelle hat jedoch keinerlei biologische Bedeutung. Wie die Abbildung zeigt, beeinflusst das Signifikanzlevel auch den Type 2 Fehler.
Ein- oder Zweiseitig?
Wenn man sich zum Beispiel für die 5% Hürde nach Fischer entscheidet, bleibt noch die Frage, wie man die 5% verteilt. Denn im Gegensatz zu vorherigen Abbildung könnte man sich auch für einen zweiseitige Signifikanzhürde entscheiden:
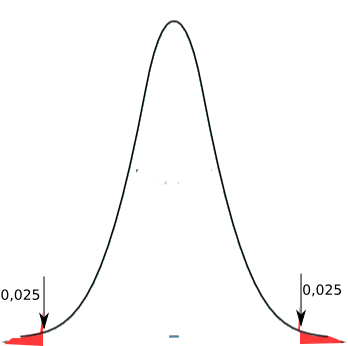
Ob man Ein- oder Zweiseitig testet, ist von der Fragestellung abhängig. Wenn auf Grund des Problems eine Abweichung nur in eine Richtung möglich ist, wäre es sinnlos in beide Richtungen zu testen. So sind die Kirschen ein gutes Beispiel für einen Einseitigen Test, weil es keinen Sinn macht, bei extrem süßen Kirschen, die Alternativhypothese anzunehmen, dass es sich um eine Sauerkirsche handelt. Wenn man aber zum Beispiel eine Futtermischung auf ihren Einfluss auf das Wachstum von Jungtieren untersucht, hat es Sinn, in beide Richtungen zu testen, weil sich das Futter sowohl positiv, wie als auch negativ auf das Wachstum auswirken könnte.
Power und Spezifität eines Tests
Bei einem statistischen Test gibt es insgesamt 4 mögliche Ausgänge:

- Power: Die Power eines Tests gibt an, wie hoch die Wahrscheinlichkeit ist, dass man sich für die Alternativhypothese entscheidet, wenn diese auch wahr ist. Die Wahrscheinlichkeit berechnet sich: Power = 1 - Type2-Fehler.
- Spezifität: Die Spezifität eines Tests gibt an, wie hoch die Wahrscheinlichkeit ist, dass man die Nullhypothese beibehält, wenn diese auch wahr ist.
Die zwei verschiedenen Typen von Tests
Bei statistischen Tests unterscheidet man allgemein zwei verschiedene Typen von Tests:
- Parametrische Tests setzten das Wissen über die statistischen Größen der Grundgesamtheit voraus. Bei parametrischen Tests werden Größen der beschreibenden Statistik aus der Grundgesamtheit herangezogen, um zu entscheiden, ob die Stichprobe aus der Grundgesamtheit, oder aus einer alternativen Verteilung stammt.
- Nichtparametrische Tests setzen kein Wissen über die statistischen Größen der Grundgesamtheit voraus. Bei den nichtparametrischen Tests wird mit verschiedenen Verfahren eine synthetische Verteilung erzeugt, woraus die Größen der beschreibenden Statistik gerechnet werden können. Eine typische Anwendung wäre zum Beispiel das Vergleichen von Mittelwerten aus 2 Stichproben.
\(\chi^2 \) - Anpassungstest
Der \( \chi^2 \) Anpasungstest überprüft, ob ein Merkmal einer hypothetischen Verteilung entspricht. Dabei ist die Wahrscheinlichkeit des Merkmals in der Grundgesamtheit unbekannt, so dass eine hypothetische Verteilung angenommen wird. Man berechnet dann mit Hilfe der vermuteten Verteilung \( F_0(x) \) die zu erwartende Realisierung des Merkmals unter Annahme der vermuteten Verteilung \( E(n_{j0})\). Mit Hilfe der Formel: \[ \chi^2 = \sum_{j=1}^{m}\frac{\left( n_j-E(n_{j0})\right) ^2}{E(n_{j0})} \]
lässt sich die Prüfgröße \( \chi^2 \) berechnen, welche selbst der \( \chi^2\)-Verteilung entspricht. Über die Verteilung der Prüfgröße lässt sich dann eine Aussage zur Signifikanz machen. Ein Beispiel soll das veranschaulichen:
\( \chi^2 \) Anpassungstest -- Ein Beispiel
Für einen dominant rezessiven Erbgang nach der 2. Mendelschen Regel für die Blütenfarbe von Erbsen erwartet man in der \( F_2\)-Generation eine Aufspaltung in 3:1. Dies soll die hypothetische Verteilung für ein genetisches Experiment sein. Mit Hilfe des \( \chi^2 \) Anpassungstests wollen wir eine Aussage darüber treffen, ob unsere genetisch manipulierten Erbsen ebenfalls eine 3:1 Aufspaltung der Blütenfarbe haben, oder ob die Aufspaltung signifikant anders ist. Als Signifikanzhürde wählen wir nach Fischer \( \alpha<0.05 \) Es wurde die Blütenfarbe von 100 Erbsen ausgezählt, mit folgendem Ergebnis:

Mit Hilfe der Formel berechnet sich die Prüfgröße wie folgt: \[ \chi^2 = \frac{(85-75)^2}{75} + \frac{(15-25)^2}{25} = 5.33 \]
Um die berechnete Prüfgröße beurteilen zu können, benötigt man die zum Problem passende \( \chi^2\)-Verteilung. Folgender R-Code simuliert 1000 zufällige Stichproben aus der hypothetischen Grundgesamtheit und zeigt die \( \chi^2\)-Verteilung als Histogram an:
> p <- c(0.333, 0.666)
> x <- c(1,2)
> chi <- rep(0,1000)
> for ( i in c(1:1000) ) {
+ tmp <- sample(x,1000,replace=TRUE,prob=p)
+ chi[i] <- ((sum(tmp[]==1)-333)^2/333) + ((sum(tmp[]==2)-667)^2/667)
+ }
> hist( chi, freq=FALSE, xlab=expression(chi^2) )
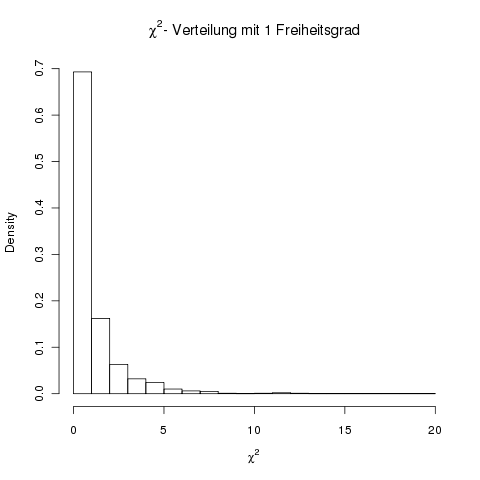
Die Testgröße \( \chi^2 \) berechnet sich aus nur 2 Kategorien (weiß,rot) und besitzt deshalb nur 1 Freiheitsgrad. Der Wert für das 95%-Quantil berechnet sich mit R wie folgt:
> qchisq(0.95,1) [1] 3.841459
Die Signifikanzhürde für die \( \chi^2\)-Verteilung mit einem Freiheitsgrad liegt also bei \( 3.84\), womit unsere genetisch manipulierten Erbsen mit \( \chi^2=5.33 \) signifikant von der Mendelschen Vererbung abweichen.
Problem der kleinen Stichprobe
Dem aufmerksamen Leser ist wahrscheinlich im R Code für das Histogramm der \( \chi^2\)-Verteilung aufgefallen, dass die Stichprobe auf 1000 vergrößert wurde. Das Problem der kleinen Stichprobe wurde bereits angesprochen, so kommt es bei kleinen Stichproben zu einer Überbewertung von extremen Werten. Im Beispiel mit den genetisch veränderten Erbsen ergibt sich damit die Frage, ob unsere Prüfgröße \( \chi^2=5.33 \) auch zufriedenstellend \( \chi^2 \) verteilt ist, oder ob die Stichprobe zu klein ist. Wenn dem so ist hat das zur Folge, dass zufällige extreme Werte überbewertet werden und damit auch das 95% Quantil größer ist. Wir machen also einen erhöhten Typ 1 Fehler. Der folgende R Code simuliert die \( \chi^2 \) Verteilung von 1000 Stichproben der Größe 100 und stellt das Ergebnis in einem Histogramm dar:
> p <- c(0.333, 0.666)
> x <- c(1,2)
> chi <- rep(0,1000)
> for ( i in c(1:1000) ) {
+ tmp <- sample(x,100,replace=TRUE,prob=p)
+ chi[i] <- ((sum(tmp[]==1)-25)^2/25) + ((sum(tmp[]==2)-75)^2/75)
+ }
> hist( chi, freq=FALSE, xlab=expression(chi^2) )
Die folgende Abbildung zeigt beide Histogramme im Vergleich und markiert mit einem Pfeil das Ende des 95% Quantils der \( \chi^2\)-Verteilung der kleinen Stichprobe.

Man erkennt deutlich, dass sich beide Verteilungen stark unterscheiden und die Signifikanzhürde ein 3 faches größer ist. Mit diesem Ergebnis zeigt, dass ein statistischer Test nur so gut sein kann, wie die erfüllten Voraussetzungen.
Die Korrektur
der \( \chi^2 \) Verteilung ist vor allem nötig, wenn es sich um eine Verteilung mit nur einem Freiheitsgrad handelt. Die sogenannte Yates' Korrektur verbessert dabei die Vergleichbarkeit der Testgröße mit der theoretischen Verteilung bei kleinen Stichproben mit nur einem Freiheitsgrad. \[ \chi^2_{kor}=\sum^n_{i=1} \frac{(|n_j-E(n_{j0})|-0.5)^2}{E(n_{j0})} \]
Wie an der Formel deutlich wird, verliert die Korrektur mit der Größe der Stichprobe an Bedeutung. Aus diesem Grund lässt sich die Korrektur gefahrlos immer bei eine \( \chi^2\)-Verteilung mit nur einem Freiheitsgrad anwenden! Die korrigierte Testgröße aus dem Beispiel mit der Blütenfarbe der genetisch veränderten Erbsen beträgt: \[ \chi^2_{korr} = \frac{(|85-75|-0.5)^2}{75} + \frac{(|15-25|-0.5)^2}{25} = 4.81 \]
Voraussetzungen für den \( \chi^2\)-Test
Nachdem das Vorgehen beim \( chi^2\)-Test und bereits die Probleme von kleinen Stichproben besprochen wurden, muss abschließend noch etwas zu den Voraussetzungen für den Test gesagt werden. Der Test geht davon aus, dass sich die Daten gegenseitig ausschließen und sich gegenseitig bedingen. Der häufigste Fehler ist dabei, die Daten in unbrauchbare Kategorien einzuteilen. Sie sind zum Beispiel daran interessiert, ob eine genetisch veränderte Pflanze seltener von Parasiten heimgesucht wird. Dafür stellen Sie Fallen an 2 Pflanzen auf und zählen nach 1 Tag die jeweiligen Schädlinge in der Falle. Diese Daten lassen sich nicht mit einem \( \chi^2 \) Test auswerten, weil sich die Daten nicht gegenseitig bedingen. Wenn ein Schädling nicht in der einen Falle ist, muss er nicht zwangsläufig in der anderen Falle sein, weil es möglich ist, dass dieser in keine Falle gegangen ist.
Monte-Carlo-Statistik
Das Verfahren was genutzt wurde, um die \( \chi^2\)-Verteilungen als Histogramm darzustellen, nennt man auch Monte-Carlo-Statistik. Dabei handelt es sich um eine große Anzahl von Zufallsversuchen, um ein statistisches Problem numerisch zu lösen.