Eine Regression in R ist vielleicht etwas ungewohnt, dafür liefert diese in kürzester Zeit Regressionen für jedes nur erdenkliche Modell und gibt mit nur wenigen Befehlen Statistiken zu den Residuen aus.

Für die Regression laden wir die Daten von Anscombe:
> attach(anscombe) # die Daten in den Suchpfad aufnehmen
> anscombe
x1 x2 x3 x4 y1 y2 y3 y4
1 10 10 10 8 8.04 9.14 7.46 6.58
2 8 8 8 8 6.95 8.14 6.77 5.76
3 13 13 13 8 7.58 8.74 12.74 7.71
4 9 9 9 8 8.81 8.77 7.11 8.84
...
> par.backup <- par(mfrow=c(2,2))
> par.backup
$mfrow
[1] 1 1
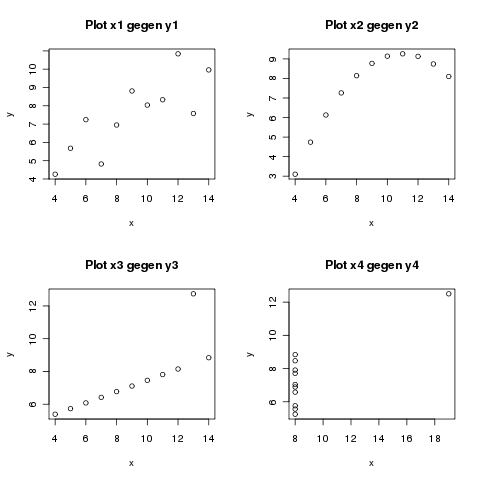
> for(i in 1:4) {
+ x <- get( paste("x", i, sep=""))
+ y <- get( paste("x", i, sep=""))
+ plot(x, y, main=paste("Plot x", i, " gegen y", i, sep="" ))
+ }
Der R-Code lädt die Anscombe Daten, welche 4 verschiedene Messreihen enthalten. Als nächstes wird die Grafik in 4 Subgrafiken unterteilt und die alten Einstellungen in par.backup gespeichert. Darauf folgt eine gezählte Schleife, welche mit for(){} aufgerufen wird. Innerhalb der runden Klammern steht dabei die Variable, die gezählt werden soll. In diesem Beispiel wird die Variable i von 1 auf 4 gezählt. Innerhalb der Schleife werden aus dem Datensatz die zusammengehörenden Variablen x1, x2, x3, x4 und y1, y2, y3, y4 in jedem Durchgang in den Variablen x und y gespeichert und abschließend mit der Funktion plot() als Scatterplot dargestellt. Die Funktion paste(Argument1, Argument2,..., sep=) setzt dabei die verschiedenen Argumente mit dem in sep= angegebenen Trennzeichen zusammen.
Modelle beschreiben
R besitzt die Möglichkeit, jedes Modell gegen Daten zu fitten. Alles was dafür nötig ist, ist das Modell in einer für R verständlichen Form zu beschreiben. Und das ist auch die einzige Hürde, die es zu meistern gilt! Ein Modell wird dabei mit einer Formel beschrieben, für die es eine eigene Notation gibt. So existieren verschiedene Operatoren, die man innerhalb der Formel verwenden kann:

Ein paar Beispiele sollen das verdeutlichen: Sie wollen folgende Formel als Modell in R darstellen: \[ y = \alpha_0 +\alpha_1x_1 + \alpha_2x_2 + \epsilon \] Die abhängige Variable ist hierbei \( y \) und die unabhängigen Variablen sind \( x_1 \) und \( x_2\). Die Verschiebung des Modells an der y-Achse ist in der Standardeinstellung enthalten und \( \epsilon \) entspricht den Residuen zwischen Modell und Datensatz. Das Modell in Formelnotation in R wäre folgendes:
y ~ x1 + x2
Ist eine Verschiebung auf der y-Achse zum Beispiel nicht erwünscht, so sähe die Formel: \[ y = \alpha_1x_1 + \alpha_2x_2 + \epsilon \] als Modell in R folgender Maßen aus:
y ~ x1 +x2 -1
Funktionen im Zusammenhang mit Modellen

Lineare Regression
Die Funktion in R für lineare Regression lautet \verb+lm()+ Die Abbildung zeigt, dass es sich im Plot x1 gegen y1 wahrscheinlich um einen linearen Zusammenhang handelt. Eine lineare Regression nach der Formel: \[ y = \alpha_0 + \alpha_1x + \epsilon \] entspricht dem Modell \verb+y~x+ in R. Folgender Code erzeugt eine lineare Regression:
> reg.lin <- lm(y1~x1, data=anscombe) # lineare Regression
> reg.lin
Call:
lm(formula = y1 ~ x1, data = anscombe)
Coefficients:
(Intercept) x1
3.0001 0.5001
> summary(reg.lin)
Call:
lm(formula = y1 ~ x1, data = anscombe)
Residuals:
Min 1Q Median 3Q Max
-1.92127 -0.45577 -0.04136 0.70941 1.83882
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.0001 1.1247 2.667 0.02573 *
x1 0.5001 0.1179 4.241 0.00217 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.237 on 9 degrees of freedom
Multiple R-squared: 0.6665, Adjusted R-squared: 0.6295
F-statistic: 17.99 on 1 and 9 DF, p-value: 0.002170
> res <- residuals(reg.lin)
> res
1 2 3 4 5 6
0.03900000 -0.05081818 -1.92127273 1.30909091 -0.17109091 -0.04136364
7 8 9 10 11
1.23936364 -0.74045455 1.83881818 -1.68072727 0.17945455
> reg.lin.2 <- lm(y1~x1 -1, data=anscombe)
> summary(reg.lin.2)
Call:
lm(formula = y1 ~ x1 - 1, data = anscombe)
Residuals:
Min 1Q Median 3Q Max
-2.7784 -0.5962 0.5756 1.4586 2.4592
Coefficients:
Estimate Std. Error t value Pr(>|t|)
x1 0.79680 0.04962 16.06 1.81e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.57 on 10 degrees of freedom
Multiple R-squared: 0.9627, Adjusted R-squared: 0.9589
F-statistic: 257.9 on 1 and 10 DF, p-value: 1.812e-08
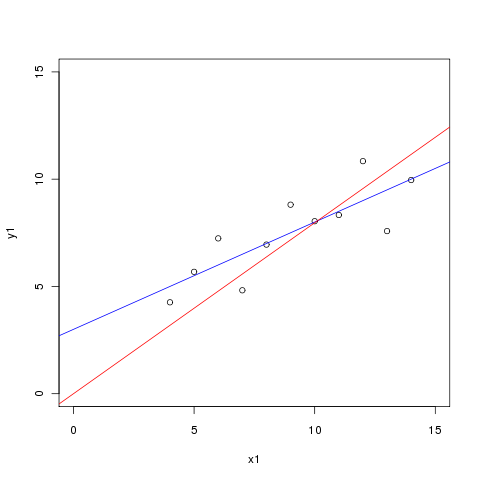
> plot(x1, y1, xlim=c(0,15), ylim=c(0,15))
> abline(reg.lin, col="blue")
> abline(reg.lin.2, col="red")
Sie können außerdem noch mit der Funktion plot() verschiedene Grafiken zur Residualanalyse ausgeben lassen:
> par(mfrow=c(2,2)) > plot(reg.lin)
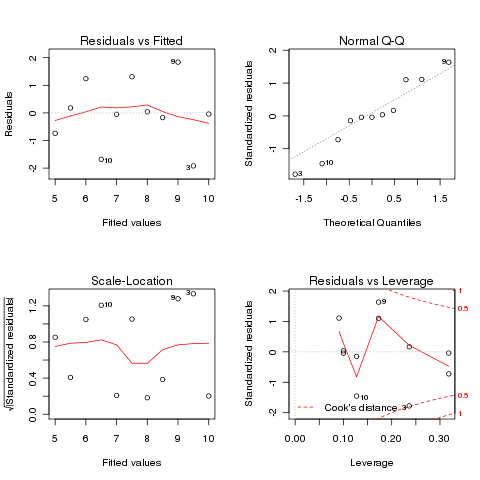
Residual vs Fitted Der klassische Residualplot trägt die Residuen gegen die angepassten Werte auf. Idealerweise sollten die Residuen dabei Null sein, was der gestrichelten Linie entspricht. Die tatsächlichen Residuen sind mit Hilfe der roten Linie eingezeichnet.
- Normal Q-Q In diesem Plot sind die Residuen normalisiert worden und gegen die theoretischen Quantilen der Standardnormalverteilung aufgetragen. Idealer Weise sollten die Residuen normalverteilt sein und auf der gestrichelten Linie liegen. In diesem Plot lassen sich zum Beispiel systematisch abweichende Funktionswerte erkennen.
- Scale-Location Dieser Plot korrigiert eine schiefe Verteilung.
- Leverage Plot Der letzte Plot zeigt den Einfluss der Residuen auf das angepasste Modell. Mit Hilfe der gestrichelten Linien wird der Cook's Abstand verdeutlicht. Dieser Abstand gibt an, wie groß der Effekt auf das Modell ist, wenn man diesen Wert entfernen würde. Dies hilft bei der Entscheidung, wie man potentielle Ausreißer behandeln möchte.
Werte vorhersagen
Mit Hilfe der Funktion predict() lassen sich aus dem Modell weitere Werte vorhersagen. Dabei benötigt die Funktion als 2. Argument ein data.frame mit den zu verwendenden neuen Werten für die Vorhersage.
> new <- data.frame(x1=seq(-20,20,0.5))
> reg.pred.p <- predict(reg.lin, new, interval="prediction")
> reg.pred.c <- predict(reg.lin, new, interval="confidence")
> matplot(new$x1, cbind(reg.pred.p, reg.pred.c[,-1]),
+ lty=c(1,2,2,3,3), col=c(1,2,2,3,3), type="l", ylab="predicted y")
> points(x1,y1)
> legend(5,-5, legend=c("predicted y", "pred. interval", "confidence
+ interval"), lty=c(1,2,3), col=c(1,2,3))
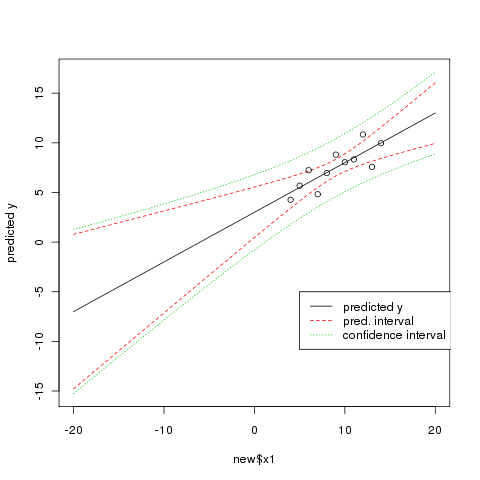
Nichtlineare Regression
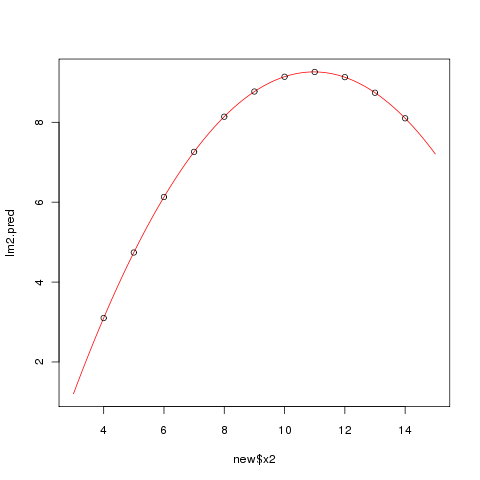
Um in R nichtlineare Modelle zu fitten, muss man die Funktion nls() verwenden, welche für nonlinear least squares steht. In der vorherigen Abbildung erkennt man, dass die Daten \( y_2 \) \( x_2 \) einem quadratischen Modell folgen.
> reg.quad <- nls(y2 ~ a*x2^2 + b*x2 + c, data=anscombe,
+ start=list(a=1, b=1, c=1))
> summary(reg.quad)
Formula: y2 ~ a * x2^2 + b * x2 + c
Parameters:
Estimate Std. Error t value Pr(>|t|)
a -0.1267133 0.0000571 -2219 <2e-16 ***
b 2.7808392 0.0010401 2674 <2e-16 ***
c -5.9957343 0.0043299 -1385 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.001672 on 8 degrees of freedom
Number of iterations to convergence: 1
Achieved convergence tolerance: 6.097e-08
>fitted(reg.quad)
[1] 9.141329 8.141329 8.740629 8.768042 9.261189 8.100210 6.127622 3.100210
[9] 9.127622 7.261189 4.740629
attr(,"label")
[1] "Fitted values"
Im Aufruf von nls() wird als erstes das entsprechende Modell definiert (hier eine klassische Parabel \( y=ax^2+bx+c\) ), gefolgt von den entsprechenden Daten. Zusätzlich benötigt die Funktion eine Liste mit Startwerten für die einzelnen Koeffizienten, welche mit start= übergeben wird. Die Funktion summary() zeigt eine Zusammenfassung der Statistik des Fits an und mit Hilfe der Funktion fitted() lassen sich die mit Hilfe des Modells angepassten Werte ausgeben.
> new <- data.frame(x2=seq(3,15,0.05)) > lm2.pred <- predict(lm2,new) > plot(new$x2, lm2.pred, type="l", col=2) > points(x2, y2)
Grafiken mit R erstellen
R besitzt vielfältige Möglichkeiten verschiedene Grafiken zu erstellen. Dabei unterscheidet man ganz allgemein zwischen \emph{high-level} und \emph{low-level}-Funktionen. Dabei erzeugen die high-level Funktionen komplette Grafiken mit Achsenbeschriftung etc. Mit low-level-Funktionen können dagegen verschiedene Elemente zu einer Grafik hinzugefügt werden (z.Bsp. Pfeile, Legenden etc.) Die Grafiken werden dabei auf einem so genannten Device ausgegeben, wo verschiedene Devices zur Auswahl stehen:

Als optionales Argument kann man den Funktionen für die verschiedenen Devices auch einen Dateinamen übergeben: png("Grafik1.png") Außerdem sind Angaben über die Größe und Auflösung möglich. (siehe Hilfe) Nach dem die Grafik fertig erstellt wurde, muss das Grafikdevice noch mit dev.off() geschlossen werden, damit die Bilddateien von anderen Programmen gelesen werden können!

Die verschiedenen Grafikfunktionen besitzen eine Menge zusätzlicher Parameter, mit denen sich das Aussehen der Grafik beeinflussen lässt. So kann man die Achsenbeschriftung, den Titel und die Farben einstellen. Zu den einzelnen Möglichkeiten muss man die Hilfe lesen, hier jedoch ein paar sehr allgemeine Parameter, die meistens unterstützt werden:
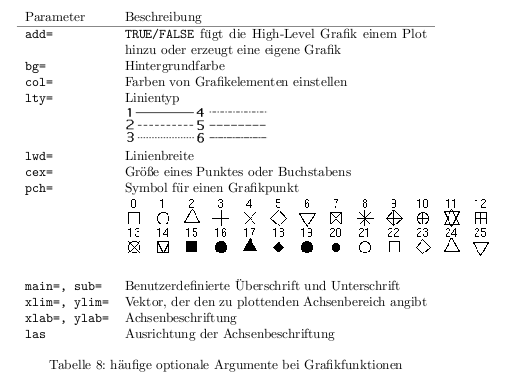
Grafikparameter mit par() ändern
par() ist eine sehr mächtige Grafikfunktion, mit der sich alle Einstellungen rund um Grafiken in R ändern lassen. Von den Einstellungen zu den Rändern bis hin zur Unterteilung in Untergrafiken. Die Möglichkeiten sind vielseitig und würden hier den Rahmen sprengen, deshalb sei auf die Hilfe verwiesen: ?par Die häufigste Änderung ist dabei das erzeugen von Untergrafiken. Das Beispiel erzeugt einen Plot mit 4 Untergrafiken:
> par(mfrow = c(2,2))
> for (i in 1:4){
+ curve(x^i, from= -3, to=3, lty=i)
+ }
Der Befehl zum Unterteilen des Grafikfensters in Untergrafiken lautet mfrow= und ist ein Argument der Funktion par(). Dabei wird in einem Vektor die Anzahl der Spalten und Zeilen übergeben. Es bietet sich an, die alten Einstellungen in einem Objekt zu speichern, um sie zurück setzen zu können. Dies ist vor allem nützlich, wenn man mit verschiedenen Argumenten experimentiert:
> par.back <- par(mfrow = c(2,2)) # speichern der alten Einstellungen
> par(par.back) # alte Einstellungen
# wiederherstellen
Ein umfangreicher Beispiel-Plot
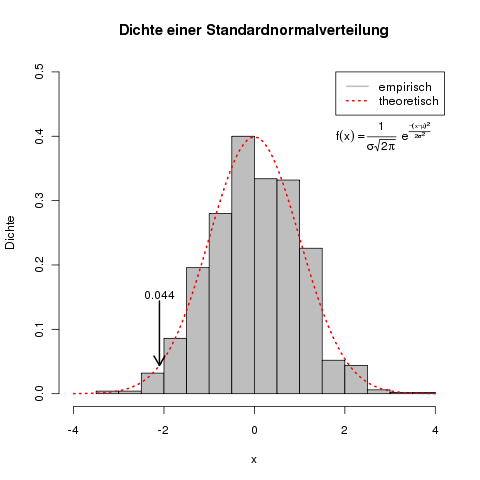
> png()
> set.seed(10)
> x <- rnorm(1000)
> hist(x, freq=FALSE, xlim=c(-4,4), ylim=c(0,0.5), ylab="Dichte",
main="Dichte einer Standardnormalverteilung", col="grey")
> curve(dnorm, from=-4, to=4, add=TRUE, lty=3, lwd=2, col="red")
>legend(2, 0.5, legend=c("empirisch", "theoretisch"),
+ col=c("grey","red"), lwd=2, lty=c(1,3))
> arrows(-2.1, dnorm(-2.1)+0.1, -2.1, dnorm(-2.1), length=0.15, code=2,lwd=2)
> text(-2.1,dnorm(-2.1)+0.11, labels=signif(dnorm(-2.1),3))
> text(2, 0.4, adj=0, cex=1,
+ expression(f(x)==frac(1,sigma*sqrt(2*pi)) ~~
+ e^{frac(-(x-mu)^2,2*sigma^2)}))
> dev.off()